Isolation, coordination & communication
This is the part of the series on getting better as a programmer. The articles are:
- Getting better at programming
- Writing programs
- Quality assurance & operations
- Debugging & exploration
- Mechanical sympathy
- Data persistence
- Isolation, coordination, & communication
- Human communication & behavior
- Development process & architecture
- Self management
- Context
- Domain specific knowledge
To motivate this discussion, consider two email systems. The first,
sendmail, is the traditional Unix program that handles
moving email around the Internet. It is known for an incomprehensible
configuration file format and a long series of security holes. The
second, qmail, has had only one potential security issue.
What is the difference?
Sending email requires access to many parts of the system. The
program must be able to read and write to users mailboxes in their home
directories, including the root user. It must be able to
write to its own spaces where it maintains state. Effectively, it has
the keys to the kingdom.
sendmail runs as a single process. Every piece of code
in sendmail has access to the entire system.
qmail isolates the parts that need access to specific parts
of the system to their own processes, and those processes communicate
via strict, minimal interfaces.
This comparison illustrates the importance of being able to isolate pieces of your system. In total isolation, though, the only thing a program can result in is the computer producing heat and entropy, so we need to be able to break that isolation in specific ways to communicate with other parts of the world. Finally, as soon as we start thinking about our system as a collection of isolated, communicating parts, we need to figure out how to coordinate those parts.
Isolation
We isolate pieces of the system for three reasons. The first we
illustrated above by comparing sendmail and
qmail. The latter isolates its parts so it can grant
permissions to only certain pieces of the system. In information
security this approach goes by the name ‘principle of least privilege.’
Everything should have only the privileges and capabilities that it
needs. Granting the least possible privilege requires that you have
isolated your program into pieces that you can grant separate privileges
to.
The second reason to isolate pieces of your program is to have them run in different places. The most ubiquitous example today is web applications, where have JavaScript running in the browser and other code running on the server. We could have the client submit forms and read complete HTML documents for every user interaction, but often we have isolated some behavior in order to be able to compute on the client without waiting for the round trip to the server.
Finally, sometimes we isolate for reasons of logistics, such as when we split a single service into microservices. Microservices lets you deploy updates to one part of the system without having to deploy the whole system. If a team of a few hundred people has subteams that only make changes to certain parts of the system, isolating their parts into microservices can change a pileup of everyone trying to get their stuff in before a release goes out into smaller teams that don’t have as much contention.
Logistics also manifests in scaling hardware and other resources that system needs. If two different parts of the system have different limiting hardware resources and scale separately, such as a web service where most of the work is handling requests and is RAM limited, but there are a few tasks that require lots of time on GPUs, splitting the GPU-limited tasks lets you have two pools of machines, each with optimized hardware, and each changing size separately as needed.
The other way logistics shows up is in preventing accidental collisions. Do two pieces of software both expect to access a directory by the same name? Does one need one version of a runtime and the othe a different version? The are many, many ways this kind of mess can show up, and often, especially for old, proprietary software, the best way out is not to try to harmonize them at all, but just to isolate them and the environments they expect from each other.
The basic unit of isolation on basically every system you will see today is the process. By default, most operating systems isolate a process’s memory, CPU registers, call stack, open files and resources, and permissions. The Therac-25 disaster shows how important this isolation is, as accidentally writing to another process’s memory led to people’s deaths. Most operating systems also provide threads within a process which isolate CPU registers and call stack from other threads, but share memory, resources, and permissions with them.
This default isn’t an inevitable or universal model, and mature operating systems provide ways to isolate them further or to break isolation in specific ways. The Linux kernel, for example, lets you create variations that are between process and thread, or to set permissions on a per-thread basis. You can generally map a segment of memory to be shared between two processes. When a Unix process creates another process, that process inherits copy of its parent’s files and resources.
In the other direction, you can isolate processes even further so they cannot even see other processes, cannot see the same file system, or their view of the network is entirely different. Each operating system does this differently. On FreeBSD these are calls jails. Solaris has zones. Windows calls them sandboxes. Linux provides the various forms of isolation independently, but they get packaged in a user visible way as containers. They’re different in details and in the exact additional isolation they provide, but the idea is the same. These various mechanisms are not portable among operating systems, though. Threads in processes are the most widely shared option, and if you need to write code that works on a wide range of systems, this is probably what you will use, though even that has significant differences between Unix-like and Windows systems.
Communication
At the beginning, I pointed out that a completely isolated process can’t do anything except produce heat and entropy, which is probably not what we want, so we need a way for it to communicate in a controlled way with other parts of the world. After decades of use, most programmers break communication into two rough approaches that function very differently:
- Shared memory, where two isolated pieces share a scratch pad that they can both read from and write to.
- Message passing, where two isolated pieces send messages to each other and act in response to receiving them.
The simplest examples of each, so we can do a first comparison, are two threads in the same process, and so which see the same memory, and two processes with a Unix domain socket between them. The Unix domain socket is a two way channel that each process can send messages over.
Say I have a large array of data that one piece of the system produces, and the other one needs to process. With the two threads, I write the data in one thread and the other reads it. With the two processes connected by a socket, I create the array in one process, serialize it into a message, and send it over the socket. The other receives the message, deserializes it, processes it, and probably sends a message back that it is done. The two threads are going to be much faster, since I didn’t have to serialize, copy, and deserialie the data.
On the other hand, imagine I get the length of the array wrong in the second thread. Now I am off writing into memory containing who knows what, and perhaps destroying state that the first thread needs.
This is the typical tradeoff between shared memory and message passing. Shared memory is almost always faster because you don’t have to copy anything. Message passing is almost always safer because you haven’t given up on isolation.
The various communication mechanisms that our field has invented often mix shared memory and message passing in interesting ways. For example, the L4 microkernel, which solved the performance problems that had plagued older microkernels like Mach, implemented message passing among processes by remapping memory from one process to another instead of copying it.
In the other direction, most desktop and server operating systems today let you map a specific range of memory into multiple processes, often backed by a file as well. The two processes can share that hunk of memory as a scratch pad, while the rest of their memory remains isolated.
When you leave the realm of a single computer, shared memory no longer provides the performance benefits we mentioned above, for the simple reason that there is no memory to be shared between two processes running on different computers. We may provide a shared memory abstraction for convenience, but it must be implemented via message passing.
Why would we want an abstraction that pretends to be shared memory? Consider this case: I have many parts of the system producing data, and many others reading what is produced.
In shared memory, I can provide a single scratchpad that all producers write to and all readers read from. Adding a new producer or a new reader doesn’t require any change to the rest of them.
In message passing, if I add a reader, each producer must be told about it so it can send messages to it as well as to the existing readers. I have to modify much of the system to add one more reader.
Shared memory is a better abstraction because the scratchpad becomes a bottleneck where we can decouple the producers and readers from knowledge of each other. This is the entire basis for databases.
The jump from message passing within a computer to message passing between computers has one more big difference. It is no longer reliable. You can no longer assume that the other computer is running or reachable. So you can send a message and hope for the best, or send a message, await an acknowledgement, and, if it doesn’t arrive within some period of time, send the message again. We call these at-most-once and at-least-once delivery, and you can only pick one. There is no exactly once delivery. The choices around this bring us to our next topic.
Coordination
When we start thinking of a system as a collection of parts, we have to figure out how to coordinate those parts. We’ll begin with a very simple case of a set of modules running in the same program, all in the same process and thread. All communication is among them is reliable and only one thing is happening at a time.
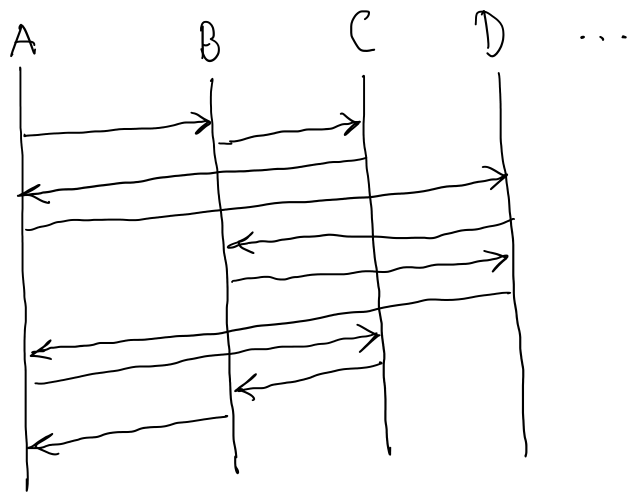
If we draw a UML sequence diagram of the calls among these modules, in general the line of calls could jump around anywhere. Requiring one thing at a time and reliable communication forces the path to unwind back out, so the first half and second half are symmetric but opposite.
Compare this to a diagram like
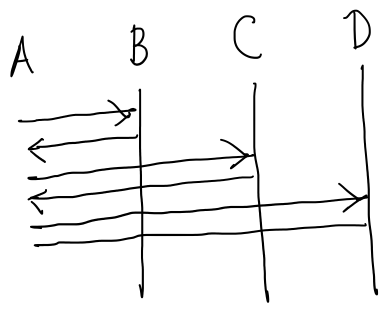
where module A calls modules B, C, and D one after another. B, C, and D never communicate. This is basically a pipeline managed by A. Or consider
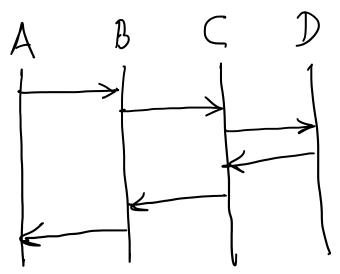
where A calls B, which calls C, which calls D. A only knows about B. B only knows about C. C only knows about D.
These two diagrams have two important properties that the first one does not:
- We can isolate a subset of the coordination and reason about that in isolation.
- Introducing a new module into the coordination correctly requires much less reasoning.
A back of the envelope calculation shows just how big a difference this can make. Consider calls in the diagram, but now with modules. With the unstructured coordination of the first diagram, each call can go to one of modules, so we have possible paths. In the second diagram, say the coordinating module A can call any of the other modules at each step. This gives us possible paths. With twenty modules,
| N |
unstructured paths |
pipline paths |
|---|---|---|
| 1 | 19 | 19 |
| 3 | 6,859 | 57 |
| 5 | 2,476,099 | 95 |
| 10 | 190 |
We can fairly easily constrain ourselves to choose the right structure among a few hundred. The chances that we don’t lose control of possible paths are basically nil.
We’ll come back to these concerns when we discuss architecture in a later essay. These numbers are important now because when we make the next step of allowing concurrency, the number of paths is going to explode exponentially from here. If you don’t start with a program that is manageable without concurrency, it will become truly unmanageable with it.
Successfully coordinating concurrent systems consists of isolating the coordination into pieces small enough to reason about and abstracted them from the logic they are coordinating enough to test them thoroughly in isolation.
For example, if you have a work queue with multiple, concurrent workers and multiple things enqueueing jobs, build the queueing system so that it is generic over the function workers run and the type of jobs. Then test it by making the type of jobs an object that you can use to control workers, and the worker a function that listens to the object for instructions. Then from your test code you can enqueue specific objects and use them to direct jobs to finish successfully or with an error in specific orders.
Designing coordination systems usually consists of drawing on a body of algorithms for solving specific parts of the problem, such as leader election or gossip to propagate information among members of the group without a leader. These get fit together in various ways, but concurrent coordination is a hard enough problem that when groups start dealing with it at any kind of scale they turn to modeling tools like TLA+ to design the coordination.
How to ascend
At the most basic level, you need to know how to start and control processes and threads on your operating system and what the mechanisms for communicating between processes are. Then spend time looking at your programs and other people’s programs and mapping them onto process diagrams among the modules you identify. And you need to learn how to communicate over a network and how that is different from local interprocess communication.
From there, to ascend in isolation you go deeper into what your operating system provides. How do you isolate processes more? How do you open controlled holes between them?
For communication, you dive into protocol design. When do you want TCP versus UDP? How do you build protocols on top of UDP? How do you design protocols so that handling them is straightforward for both parties? How will protocols handle being extended in the future? What happens when they face congestion and network problems?
For coordination, you start by learning the typical concurrency primitives like locks, semaphores, and atomic operations on numbers. Then you dive into the world of concurrent and distributed algorithms and modeling them via systems like TLA+.